配布資料の問1・問2・問3に答えてください。上記の問において???の所を、正規表現の場合はテキストで、NFAおよびDFAの場合はastah* communityで状態線伊豆を描き、保存ファイルとキャプチャ画像の両方をレポートメールに添付してください。
問1
問1のオートマトンをNFAで表すと、以下のような状態遷移となる。
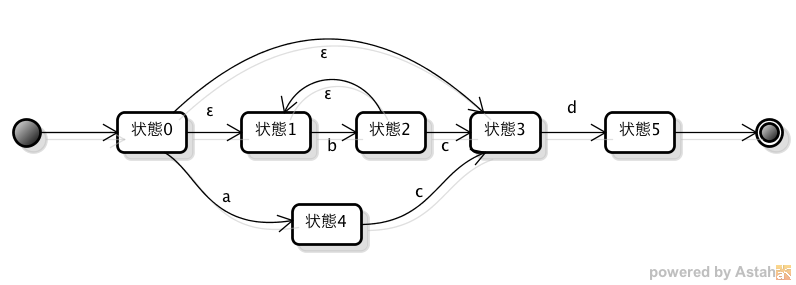
次に、問1のオートマトンをDFAで表すと、以下のような状態遷移となる。
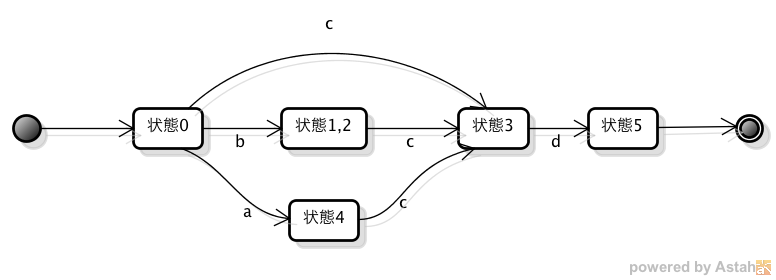
問2
問2のオートマトンを正規表現で表すと、「a(a|b)*ab」となる。そして、次にDFAで表すと、以下のような状態遷移となる。
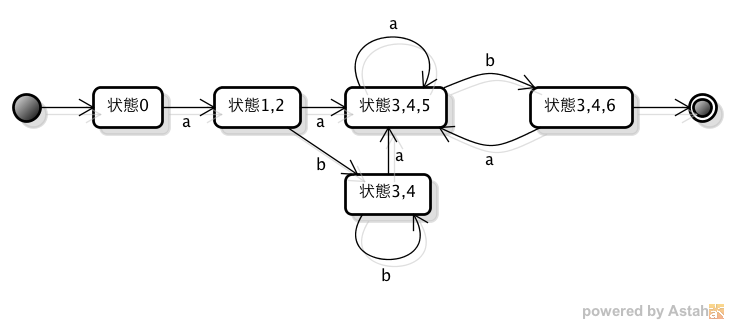
問3
問3のオートマトンを正規表現で表すと、「(a*|b*)cd」となる。そして、次にNFAで表すと、以下のような状態遷移となる。
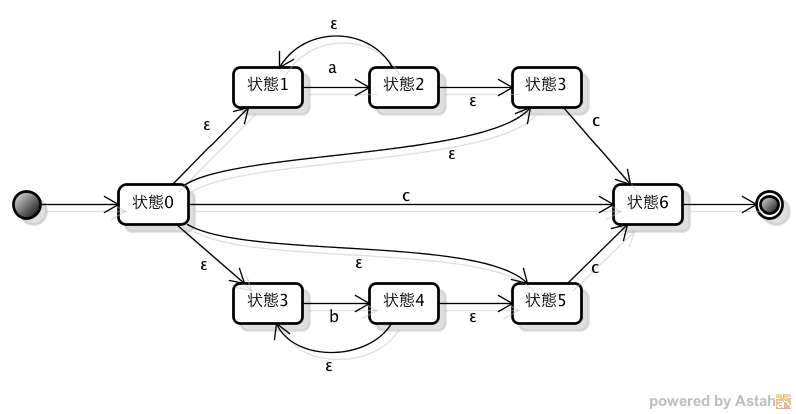
配布資料の問4において、当該のものが何であり、それを作ることが可能か否かを、上記の問1〜問3で行ったことと関連づけて記述してください。
問4
BNFのBNFによって、1文字ずつ文字列か数字列かなどが判別され、正規表現化されたが、ここでは正規表現化された文字列に演算子、制御文、変数、数字などの目印をつけるものが今回のNFAやDFAだと私は考える。つまり実際に例えると、アルファベット文字列の後に数値なら変数、そのアルファベット文字列が制御文なら制御文となるように、制御文、変数という分岐に分かれて有限オートマトンの処理していく。これを作ることは可能だと思う。なぜなら、BNFのBNFで状態遷移を解析できたということは、この正規表現をオートマトンを使って解析するという工程も可能だと思うからである。
その他、感想
問1〜問3に関して
そこまで有限オートマトンを理解できていなかったのもあり、正しいオートマトンではないと思います。もう一度有限オートマトンをしっかり理解できるように、復習します。
字句解析
BNFのBNFであったり、今回の正規表現と自動人形を学んでいく中で、今まで作ってきたifやswitchなどで場合分けした字句解析のプログラムには、欠陥があると徐々に気づき始めてきて、作り直しだなと思いました。そして、公式(一次書物に近い)ではなく、誰かが書いた(二次書物以降)本で作るのは本当にダメだなと実感しました(もちろんすごく良い物もありますが)。もしそのまま字句解析を放置していれば、オートマトンが成り立つという証明がされずに世に出されることになるので、今回の僕の描いたオートマトンのように欠陥だらけになります。読んでいた本が正しくない方式だと気づけてよかったです。それから、字句解析プログラムを書いているときに何か汚い感じと抜けがある感じがしたので、解消しました。